- Подробности
- Автор: Super User
- Категория: Linux
- Просмотров: 5405
оригинал тут http://www.k-max.name/linux/iptables-v-primerax/
Настройка netfilter/iptables для рабочей станции
Давайте начнем с элементарной задачи - реализация сетевого экрана Linux на десктопе. В большинстве случаев на десктопных дистрибутивах линукса нет острой необходимости использовать файервол, т.к. на таких дистрибутивах не запущены какие-либо сервисы, слушающие сетевые порты, но ради профилактики организовать защиту не будет лишним. Ибо ядро тоже не застраховано от дыр. Итак, мы имеем Linux, с настроенным сетевым интерфейсом eth0, не важно по DHCP или статически...
Для настройки сетевого экрана я стараюсь придерживаться следующей политики: запретить все, а потом то, что нужно разрешить. Так и поступим в данном случае. Если у вас свежеустановленная система и вы не пытались настроить на ней сетевой фильтр, то правила будут иметь примерно следующую картину:
netfilter:~# iptables -L
Chain INPUT (policy ACCEPT)
target prot opt source destination
Chain FORWARD (policy ACCEPT)
target prot opt source destination
Chain OUTPUT (policy ACCEPT)
target prot opt source destination
Это значит, что политика по умолчанию для таблицы filter во всех цепочках - ACCEPT и нет никаких других правил, что-либо запрещающих. Поэтому давайте сначала запретим ВСЁ входящие, исходящие и проходящие пакеты (не вздумайте это делать удаленно-тут же потеряете доступ):
netfilter:~# iptables -P INPUT DROP
netfilter:~# iptables -P OUTPUT DROP
netfilter:~# iptables -P FORWARD DROP
Этими командами мы устанавливаем политику DROP по умолчанию. Это значит, что любой пакет, для которого явно не задано правило, которое его разрешает, автоматически отбрасывается. Поскольку пока еще у нас не задано ни одно правило - будут отвергнуты все пакеты, которые придут на ваш компьютер, равно как и те, которые вы попытаетесь отправить в сеть. В качестве демонстрации можно попробовать пропинговать свой компьютер через интерфейс обратной петли:
netfilter:~# ping -c2 127.0.0.1
PING 127.0.0.1 (127.0.0.1) 56(84) bytes of data.
ping: sendmsg: Operation not permitted
ping: sendmsg: Operation not permitted
--- localhost ping statistics ---
2 packets transmitted, 0 received, 100% packet loss, time 1004ms
На самом деле это полностью не функционирующая сеть и это не очень хорошо, т.к. некоторые демоны используют для обмена между собой петлевой интерфейс, который после проделанных действий более не функционирует. Это может нарушить работу подобных сервисов. Поэтому в первую очередь в обязательном порядке разрешим передачу пакетов через входящий петлевой интерфейс и исходящий петлевой интерфейс в таблицах INPUT (для возможности получения отправленных пакетов) и OUTPUT (для возможности отправки пакетов) соответственно, в обязательном порядке:
netfilter:~# iptables -A INPUT -i lo -j ACCEPT
netfilter:~# iptables -A OUTPUT -o lo -j ACCEPT
После этого пинг на локалхост заработает:
netfilter:~# ping -c1 127.0.0.1
PING 127.0.0.1 (127.0.0.1) 56(84) bytes of data.
64 bytes from 127.0.0.1 (127.0.0.1): icmp_seq=1 ttl=64 time=0.116 ms
--- 127.0.0.1 ping statistics ---
1 packets transmitted, 1 received, 0% packet loss, time 116ms
rtt min/avg/max/mdev = 0.116/0.116/0.116/0.116 ms
Если подходить к настройке файервола не шибко фанатично, то можно разрешить работу протокола ICMP:
netfilter:~# iptables -A INPUT -p icmp -j ACCEPT
netfilter:~# iptables -A OUTPUT -p icmp -j ACCEPT
Более безопасно будет указать следующую аналогичную команду iptables:
netfilter:~# iptables -A INPUT -p icmp --icmp-type 0 -j ACCEPT
netfilter:~# iptables -A INPUT -p icmp --icmp-type 8 -j ACCEPT
netfilter:~# iptables -A OUTPUT -p icmp -j ACCEPT
Данная команда разрешит типы ICMP пакета эхо-запрос и эхо-ответ, что повысит безопасность.
Зная, что наш комп не заражен (ведь это так?) и он устанавливает только безопасные исходящие соединения. А так же, зная, что безопасные соединения - это соединения из т.н. эфимерного диапазона портов, который задается ядром в файле /proc/sys/net/ipv4/ip_local_port_range, можно разрешить исходящие соединения с этих безопасных портов:
netfilter:~# cat /proc/sys/net/ipv4/ip_local_port_range
32768 61000
netfilter:~# iptables -A OUTPUT -p TCP --sport 32768:61000 -j ACCEPT
netfilter:~# iptables -A OUTPUT -p UDP --sport 32768:61000 -j ACCEPT
Если подходить к ограничению исходящих пакетов не параноидально, то можно было ограничиться одной командой iptables, разрешающей все исхолящие соединения оп всем протоколам и портам:
netfilter:~# iptables -A OUTPUT -j ACCEPT
netfilter:~# # или просто задать политику по умолчанию ACCEPT для цепочки OUTPUT
netfilter:~# iptables -P OUTPUT ACCEPT
Далее, зная что в netfilter сетевые соединения имеют 4 состояния (NEW, ESTABLISHED, RELATED и INVALID) и новые исходящие соединения с локального компьютера (с состоянием NEW) у нас разрешены в прошлых двух командах iptables, что уже установленные соединения и дополнительные имеют состояния ESTABLISHED и RELATED, соответственно, а так же зная, что входящие соединения к локальной системе приходят через цепочку INPUT, можно разрешить попадание на наш компьютер только тех TCP- и UDP-пакетов, которые были запрошены локальными приложениями:
netfilter:~# iptables -A INPUT -p TCP -m state --state ESTABLISHED,RELATED -j ACCEPT
netfilter:~# iptables -A INPUT -p UDP -m state --state ESTABLISHED,RELATED -j ACCEPT
Это собственно, все! Если на десктопе все же работает какая-то сетевая служба, то необходимо добавить соответствующие правила для входящих соединений и для исходящих. Например, для работы ssh-сервера, который принимает и отправляет запросы на 22 TCP-порту, необходимо добавить следующие iptables-правила:
netfilter:~# iptables -A INPUT -i eth0 -p TCP --dport 22 -j ACCEPT
netfilter:~# iptables -A OUTPUT -o eth0 -p TCP --sport 22 -j ACCEPT
Т.е. для любого сервиса нужно добавить по одному правилу в цепочки INPUT и OUTPUT, разрешающему соответственно прием и отправку пакетов с использованием этого порта для конкретного сетевого интерфейса (если интерфейс не указывать, то будет разрешено принимать/отправлять пакеты по любому интерфейсу).
Настройка netfilter/iptables для подключения нескольких клиентов к одному соединению.
Давайте теперь рассмотрим наш Linux в качестве шлюза для локальной сети во внешнюю сеть Internet. Предположим, что интерфейс eth0 подключен к интернету и имеет IP 198.166.0.200, а интерфейс eth1 подключен к локальной сети и имеет IP 10.0.0.1. По умолчанию, в ядре Linux пересылка пакетов через цепочку FORWARD (пакетов, не предназначенных локальной системе) отключена. Чтобы включить данную функцию, необходимо задать значение 1 в файле /proc/sys/net/ipv4/ip_forward:
netfilter:~# echo 1 > /proc/sys/net/ipv4/ip_forward
Чтобы форвардинг пакетов сохранился после перезагрузки, необходимо в файле /etc/sysctl.conf раскомментировать (или просто добавить) строку net.ipv4.ip_forward=1.
Итак, у нас есть внешний адрес (198.166.0.200), в локальной сети имеется некоторое количество гипотетических клиентов, которые имеют адреса из диапазона локальной сети и посылают запросы во внешнюю сеть. Если эти клиенты будут отправлять во внешнюю сеть запросы через шлюз "как есть", без преобразования, то удаленный сервер не сможет на них ответить, т.к. обратным адресом будет получатель из "локальной сети". Для того, чтобы эта схема корректно работала, необходимо подменять адрес отправителя, на внешний адрес шлюза Linux. Это достигается за счет действия MASQUERADE (маскарадинг) в цепочке POSTROUTING, в таблице nat.
netfilter:~# iptables -A FORWARD -m conntrack --ctstate ESTABLISHED,RELATED -j ACCEPT
netfilter:~# iptables -A FORWARD -m conntrack --ctstate NEW -i eth1 -s 10.0.0.1/24 -j ACCEPT
netfilter:~# iptables -P FORWARD DROP
netfilter:~# iptables -t nat -A POSTROUTING -o eth0 -j MASQUERADE
Итак, по порядку сверху-вниз мы разрешаем уже установленные соединения в цепочке FORWARD, таблице filter, далее мы разрешаем устанавливать новые соединения в цепочке FORWARD, таблице filter, которые пришли с интерфейса eth1 и из сети 10.0.0.1/24. Все остальные пакеты, которые проходят через цепочку FORWARD - отбрасывать. Далее, выполняем маскирование (подмену адреса отправителя пакета в заголовках) всех пакетов, исходящих с интерфейса eth0.
Кроме указанных правил так же можно нужно добавить правила для фильтрации пакетов, предназначенных локальному хосту - как описано в прошлом разделе. То есть добавить запрещающие и разрешающие правила для входящих и исходящих соединений:
netfilter:~# iptables -P INPUT DROP
netfilter:~# iptables -P OUTPUT DROP
netfilter:~# iptables -A INPUT -i lo -j ACCEPT
netfilter:~# iptables -A OUTPUT -o lo -j ACCEPT
netfilter:~# iptables -A INPUT -p icmp --icmp-type 0 -j ACCEPT
netfilter:~# iptables -A INPUT -p icmp --icmp-type 8 -j ACCEPT
netfilter:~# iptables -A OUTPUT -p icmp -j ACCEPT
netfilter:~# cat /proc/sys/net/ipv4/ip_local_port_range
32768 61000
netfilter:~# iptables -A OUTPUT -p TCP --sport 32768:61000 -j ACCEPT
netfilter:~# iptables -A OUTPUT -p UDP --sport 32768:61000 -j ACCEPT
netfilter:~# iptables -A INPUT -p TCP -m state --state ESTABLISHED,RELATED -j ACCEPT
netfilter:~# iptables -A INPUT -p UDP -m state --state ESTABLISHED,RELATED -j ACCEPT
В результате, если один из хостов локальной сети, например 10.0.0.2, попытается связаться с одним из интернет-хостов, например, 93.158.134.3 (ya.ru), при проходе его пакетов через шлюз, их исходный адрес будет подменяться на внешний адрес шлюза в цепочке POSTROUTING таблице nat, то есть исходящий IP 10.0.0.2 будет заменен на 198.166.0.200. С точки зрения удаленного хоста (ya.ru), это будет выглядеть, как будто с ним связывается непосредственно сам шлюз. Когда же удаленный хост начнет ответную передачу данных, он будет адресовать их именно шлюзу, то есть 198.166.0.200. Однако, на шлюзе адрес назначения этих пакетов будет подменяться на 10.0.0.2, после чего пакеты будут передаваться настоящему получателю в локальной сети. Для такого обратного преобразования никаких дополнительных правил указывать не нужно — это будет делать все та же операция MASQUERADE, которая помнит какой хост из локальной сети отправил запрос и какому хосту необходимо вернуть пришедший ответ.
Примечание: желательно негласно принято, перед всеми командами iptables очищать цепочки, в которые будут добавляться правила:
netfilter:~# iptables -F ИМЯ_ЦЕПОЧКИ
Предоставление доступа к сервисам на шлюзе
Предположим, что на нашем шлюзе запущен некий сервис, который должен отвечать на запросы поступающие из сети интернет. Допустим он работает на некотором TCP порту nn. Чтобы предоставить доступ к данной службе, необходимо модифицировать таблицу filter в цепочке INPUT (для возможности получения сетевых пакетов, адресованных локальному сервису) и таблицу filter в цепочке OUTPUT (для разрешения ответов на пришедшие запросы).
Итак, мы имеем настроенный шлюз, который маскарадит (заменяет адрес отправителя на врешний) пакеты во внешнюю сеть. И разрешает принимать все установленные соединения. Предоставление доступа к сервису будет осуществляться с помощью следующих разрешающих правил:
netfilter:~# iptables -A INPUT -p TCP --dport nn -j ACCEPT
netfilter:~# iptables -A OUTPUT -p TCP --sport nn -j ACCEPT
Данные правила разрешают входящие соединения по протоколу tcp на порт nn и исходящие соединения по протоколу tcp с порта nn. Кроме этого, можно добавить дополнительные ограничивающие параметры, например разрешить входящие соединения только с внешнего интерфейса eth0 (ключ -i eth0) и т.п.
Предоставление доступа к сервисам в локальной сети
Предположим, что в нашей локальной сети имеется какой-то хост с IP X.Y.Z.1, который должен отвечать на сетевые запросы из внешней сети на TCP-порту xxx. Для того чтобы при обращении удаленного клиента ко внешнему IP на порт xxx происходил корректный ответ сервиса из локальной сети, необходимо направить запросы, приходящие на внешний IP порт xxx на соответствующий хост в локальной сети. Это достигается модификацией адреса получателя в пакете, приходящем на указанный порт. Это действие называется DNAT и применяется в цепочке PREROUTING в таблице nat. А так же разрешить прохождение данный пакетов в цепочке FORWARD в таблице filter.
Опять же, пойдем по пути прошлого раздела. Итак, мы имеем настроенный шлюз, который маскарадит (заменяет адрес отправителя на врешний) пакеты во внешнюю сеть. И разрешает принимать все установленные соединения. Предоставление доступа к сервису будет осуществляться с помощью следующих разрешающих правил:
netfilter:~# iptables -t nat -A PREROUTING -p tcp -d 198.166.0.200 --dport xxx -j DNAT --to-destination X.Y.Z.1
netfilter:~# iptables -A FORWARD -i eth0 -p tcp -d X.Y.Z.1 --dport xxx -j ACCEPT
Сохранение введенных правил при перезагрузке
Все введенные в консоли правила - после перезагрузки ОС будут сброшены в первоначальное состояние (читай - удалены). Для того чтобы сохранить все введенные команды iptables, существует несколько путей. Например, один из них - задать все правила брандмауэра в файле инициализации rc.local. Но у данного способа есть существенный недостаток: весь промежуток времени с запуска сетевой подсистемы, до запуска последней службы и далее скрипта rc.local из SystemV операционная система будет не защищена. Представьте ситуацию, например, если какая-нибудь служба (например NFS) стартует последней и при ее запуске произойдет какой-либо сбой и до запуска скрипта rc.local. Соответственно, rc.local так и не запуститься, а наша система превращается в одну большую дыру.
Поэтому самой лучшей идеей будет инициализировать правила netfilter/iptables при загрузке сетевой подсистемы. Для этого в Debian есть отличный инструмент - каталог /etc/network/if-up.d/, в который можно поместить скрипты, которые будут запускаться при старте сети. А так же есть команды iptables-save и iptables-restore, которые сохраняют создают дамп правил netfilter из ядра на стандартный вывод и восстанавливают в ядро правила со стандартного ввода соответственно.
Итак, алгоритм сохранения iptables примерно следующий:
- Настраиваем сетевой экран под свои нужны с помощью команды iptables
- создаем дамп созданный правил с помощью команды iptables-save > /etc/iptables.rules
- создаем скрипт импорта созданного дампа при старте сети (в каталоге /etc/network/if-up.d/) и не забываем его сделать исполняемым:
# cat /etc/network/if-up.d/firewall
#!/bin/bash
/sbin/iptables-restore < /etc/iptables.rules
exit 0
# chmod +x /etc/network/if-pre-up.d/firewall
Дамп правил, полученный командой iptables-save имеет текстовый формат, соответственно пригоден для редактирования. Синтаксис вывода команды iptables-save следующий:
# Generated by iptables-save v1.4.5 on Sat Dec 24 22:35:13 2011
*filter
:INPUT ACCEPT [0:0]
:FORWARD ACCEPT [0:0]
.......
# комментарий
-A INPUT -i lo -j ACCEPT
-A INPUT ! -i lo -d 127.0.0.0/8 -j REJECT
...........
-A FORWARD -j REJECT
COMMIT
# Completed on Sat Dec 24 22:35:13 2011
# Generated by iptables-save v1.4.5 on Sat Dec 24 22:35:13 2011
*raw
......
COMMIT
Строки, начинающиеся на # - комментарии, строки на * - это название таблиц, между названием таблицы и словом COMMIT содержатся параметры, передаваемые команде iptables. Параметр COMMIT - указывает на завершение параметров для вышеназванной таблицы. Строки, начинающиеся на двоеточие задают цепочки, в которых содержится данная таблица в формате:
:цепочка политика [пакеты:байты]
где цепочка - имя цепочки, политика - политика цепочки по-умолчанию для данной таблицы, а далее счетчики пакетов и байтов на момент выполнения команды.
В RedHat функции хранения команд iptables выполняемых при старте и останове сети выполняет файл /etc/sysconfig/iptables. А управление данным файлом лежит на демоне iptables.
Как еще один вариант сохранения правил, можно рассмотреть использование параметра up в файле /etc/network/interfaces с аргументом в виде файла, хранящего команды iptables, задающие необходимые правила.
Итог
На сегодня будет достаточно. Более сложные реализации межсетевого экрана я обязательно будут публиковаться в следующих статьях.
- Подробности
- Автор: Super User
- Категория: Linux
- Просмотров: 4293
оригинал тут http://www.k-max.name/linux/netfilter-iptables-v-linux/
Доброго времени, читатели и гости моего блога. C этой статьи начну серию статей о подсистеме Netfilter/iptables в Linux. В данной статье приведу основные понятия работы netfilter в Linux. Для понимания данной темы, обязательно советую ознакомиться со статьями Основные понятия сетей, Настройка сети в Linux, диагностика и мониторинг и Настройка и управление сетевой подсистемой Linux (iproute2).
Введение и история
Netfilter — межсетевой экран (он же, брандмауэр, он же файерволл, он же firewall...) встроен в ядро Linux с версии 2.4. Netfilter управляется утилитой iptables (Для IPv6 — ip6tables). До netfilter/iptables был Ipchains, который входил в состав ядер Linux 2.2. До ipchains в Linux был так называемый ipfw (IPV4 firewal), перенесенный из BSD. Утилита управления - ipfwadm. Проект netfilter/iptables был основан в 1998. Автором является Расти Расселл (он же руководил и прошлыми разработками). В 1999 г. образовалась команда Netfilter Core Team (сокращено coreteam). Разработанный межсетевой экран получил официальное название netfilter. В августе 2003 руководителем coreteam стал Харальд Вельте (Harald Welte).
Проекты ipchains и ipfwadm изменяли работу стека протоколов ядра Linux, поскольку до появления netfilter в архитектуре ядра не существовало возможностей для подключения дополнительных модулей управления пакетами. iptables сохранил основную идею ipfwadm — список правил, состоящих из критериев и действия, которое выполняется если пакет соответствует критериям. В ipchains была представлена новая концепция — возможность создавать новые цепочки правил и переход пакетов между цепочками, а в iptables концепция была расширена до четырёх таблиц (в современных netfilter - более четырех), разграничивающих цепочки правил по задачам: фильтрация, NAT, и модификация пакетов. Также iptables расширил возможности Linux в области определения состояний, позволяя создавать межсетевые экраны работающие на сеансовом уровне.
Архитектура Netfilter/iptables
Предварительные требования (с)
Как уже говорилось выше, для работы Netfilter необходимо ядро версии 2.6 (ну или хотя бы 2.3.15). Кроме того, при сборке и настройке ядра необходимо наличие настроек CONFIG_NETFILTER, CONFIG_IP_NF_IPTABLES, CONFIG_IP_NF_FILTER (таблица filter), CONFIG_IP_NF_NAT (таблица nat), CONFIG_BRIDGE_NETFILTER, а также многочисленные дополнительные модули: CONFIG_IP_NF_CONNTRACK (отслеживание соединений), CONFIG_IP_NF_FTP (вспомогательный модуль для отслеживания FTP соединений), CONFIG_IP_NF_MATCH_* (дополнительные типы шаблонов соответствия пакетов: LIMIT, MAC, MARK, MULTIPORT, TOS, TCPMSS, STATE, UNCLEAN, OWNER), CONFIG_IP_NF_TARGET_* (дополнительные действия в правилах: REJECT, MASQUERADE, REDIRECT, LOG, TCPMSS), CONFIG_IP_NF_COMPAT_IPCHAINS для совместимости с ipchains, CONFIG_BRIDGE_NF_EBTABLES и CONFIG_BRIDGE_EBT_* для работы в режиме моста, прочие CONFIG_IP_NF_* и CONFIG_IP6_NF_*. Полезно также указать CONFIG_PACKET.
Файлы в каталоге /proc, отображающие информацию о работе netfilter (о некоторых из них - ниже по тексту):
- /proc/net/ip_tables_names - список используемых таблиц
- /proc/net/ip_tables_targets - список используемых действий
- /proc/net/ip_tables_matches - список используемых протоколов
- /proc/net/nf_conntrack (или /proc/net/ip_conntrack) - список установленных соединений и их состояний
- /proc/sys/net/ipv4/netfilter/* - cодержит множество настроек системы conntrack, например:
- ip_conntrack_tcp_be_liberal
- 0 - все пакеты, не попадающие в окно, считаются INVALID
- 1 - только RST пакеты, не попадающие в окно, считаются INVALID (пришлось поставить)
- ip_conntrack_log_invalid - выводить в журнал INVALID пакеты
- ip_conntrack_tcp_loose - при "подхватывании" уже установленного соединения сколько пакетов требуется в обоих направлениях для подтверждения; если 0, то установленное соединение не подхватывается вовсе; по умолчанию - 3
- ip_conntrack_max_retrans - число повторных пакетов без подтверждения ACK, которое требуется для удаления соединения из таблицы после дополнительного ожидания ip_conntrack_timeout_max_retrans секунд; по умолчанию - 3
Функциональность netfilter может расширяться с помощью модулей ядра. Головной модуль ядра называется iptable_filter, модуль поддержки утилиты iptables называется ip_tables, вспомогательные модули обычно имеют префикс "ipt_" (например: ipt_state, ipt_REJECT, ipt_LOG; хотя - ip_conntrack/nf_conntrack). Большинство модулей загружается автомагически, но некоторые всё же приходиться загружать вручную (ip_conntrack_ftp - иначе может не работать в режиме Active; ip_conntrack_irc - иначе может не работать отсылка файлов по DCC; ip_nat_ftp; ip_nat_irc; ip_conntrack_tftp/nf_conntrack_tftp на клиенте - иначе не будет работать TFTP).
Схема работы
Для начального понимания архитектуры Netfilter/iptables отлично подойдет иллюстрация из википедии, которую я несколько модифицировал для большей прозрачности и понимания материала:
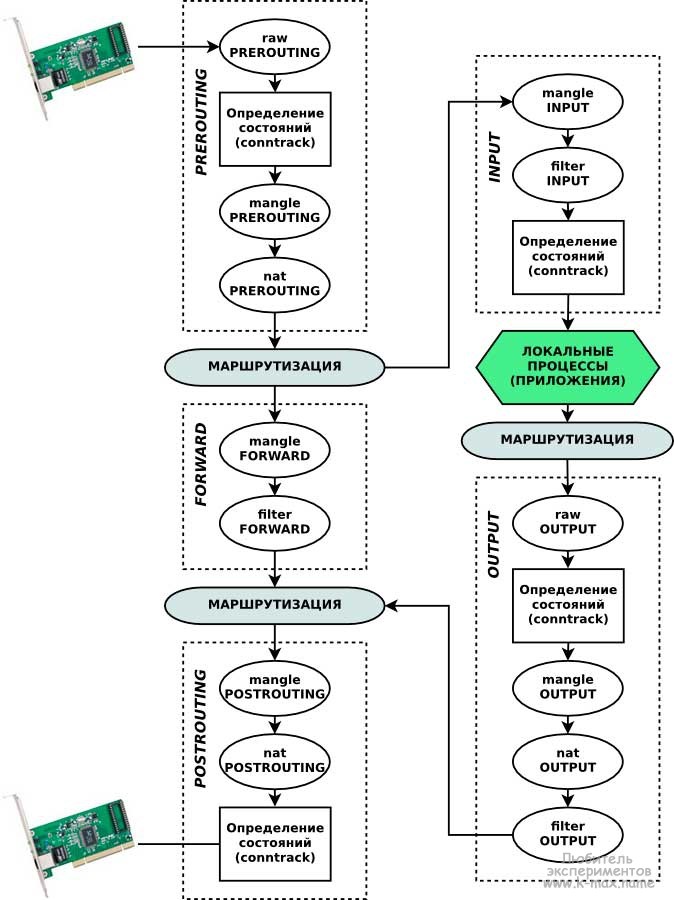
Ахтунг, ниже в трех абзацах изложена основная мысль статьи и принцип работы сетевого фильтра, поэтому желательно вчитаться как можно внимательнее!
Итак, давайте разберем данную схему работы netfilter. Сетевые пакеты поступают в сетевой интерфейс, настроенный на стек TCP/IP и после некоторых простых проверок ядром (например, контрольная сумма) проходят последовательность цепочек (chain) (обозначены пунктиром). Пакет обязательно проходит первоначальную цепочку PREROUTING. После цепочки PREROUTING, в соответствии с таблицей маршрутизации, проверяется кому принадлежит пакет и, в зависимости от назначения пакета, определяется куда он дальше попадет (в какую цепочку). Если пакет НЕ адресован (в TCP пакете поле адрес получателя - НЕ локальная система) локальной системе, то он направляется в цепочку FORWARD, если пакет адресован локальной системе, то направляется в цепочку INPUT и после прохождения INPUT отдается локальным демонам/процессам. После обработки локальной программой, при необходимости формируется ответ. Ответный пакет пакет отправляемый локальной системой в соответствии с правилами маршрутизации направляется на соответствующий маршрут (хост из локальной сети или адрес маршрутизатора) и направляется в цепочку OUTPUT. После цепочки OUTPUT (или FORWARD, если пакет был проходящий) пакет снова сверяется с правилами маршрутизации и отправляется в цепочку POSTROUTING. Может возникнуть резонный вопрос: почему несколько раз пакет проходит через таблицу маршрутизации? (об этом - ниже).
Каждая цепочка, которую проходит пакет состоит из набора таблиц (table) (обозначены овалами). Таблицы в разных цепочках имеют одинаковое наименование, но тем не менее никак между собой не связаны. Например таблица nat в цепочке PREROUTING никак не связана с таблицей nat в цепочке POSTROUTING. Каждая таблица состоит из упорядоченного набора (списка) правил. Каждое правило содержит условие, которому должен соответствовать проходящий пакет и действия к пакету, подходящему данному условию.
Проходя через серию цепочек пакет последовательно проходит каждую таблицу (в указанном на иллюстрации порядке) и в каждой таблице последовательно сверяется с каждым правилом (точнее сказать - с каждым набором условий/критериев в правиле), и если пакет соответствует какому-либо критерию, то выполняется заданное действие над пакетом. При этом, в каждой таблице (кроме пользовательских) существует заданная по-умолчанию политика. Данная политика определяет действие над пакетом, в случае, если пакет не соответствует ни одному из правил в таблице. Чаще всего - это действие ACCEPT, чтобы принять пакет и передать в следующую таблицу или DROP - чтобы отбросить пакет. В случае, если пакет не был отброшен, он завершает свое путешествие по ядру системы и отправляется в сетевую карту сетевой интерфейс, которая подходит по правилам маршрутизации.
Очень часто о таблицах и цепочках говорят в плоскости "таблицы содержат в себе наборы цепочек", но я считаю, что это неудобно и непонятно.
Цепочки netfilter:
- PREROUTING — для изначальной обработки входящих пакетов
- INPUT — для входящих пакетов, адресованных непосредственно локальному компьютеру
- FORWARD — для проходящих (маршрутизируемых) пакетов
- OUTPUT — для пакетов, создаваемых локальным компьютером (исходящих)
- POSTROUTING— для окончательной обработки исходящих пакетов
- Также можно создавать и уничтожать собственные цепочки при помощи утилиты iptables.
Цепочки организованны в 4 таблицы:
- raw — пакет проходит данную таблицу до передачи системе определения состояний. Используется редко, например для маркировки пакетов, которые НЕ должны обрабатываться системой определения состояний. Для этого в правиле указывается действие NOTRACK. Содержитcя в цепочках PREROUTING и OUTPUT.
- mangle — содержит правила модификации (обычно полей заголовка) IP‐пакетов. Среди прочего, поддерживает действия TTL, TOS, и MARK (для изменения полей TTL и TOS, и для изменения маркеров пакета). Редко необходима и может быть опасна. Содержится во всех пяти стандартных цепочках.
- nat — предназначена для подмены адреса отправителя или получателя. Данную таблицу проходят только первый пакет из потока, трансляция адресов или маскировка (подмена адреса отправителя или получателя) применяются ко всем последующим пакетам в потоке автоматически. Поддерживает действия DNAT, SNAT, MASQUERADE, REDIRECT. Содержится в цепочках PREROUTING, OUTPUT, и POSTROUTING.
- filter — основная таблица, используется по умолчанию если название таблицы не указано. Используется для фильтрации пакетов. Содержится в цепочках INPUT, FORWARD, и OUTPUT.
Как я уже отметил, непосредственно для фильтрации пакетов используются таблицЫ filter. Поэтому в рамках данной темы важно понимать, что для пакетов, предназначенных данному узлу необходимо модифицировать таблицу filter цепочки INPUT, для проходящих пакетов — цепочки FORWARD, для пакетов, созданных данным узлом — OUTPUT.
Примеры прохождения цепочек
Последовательность обработки входящего пакета, предназначенного для локального процесса:
- Просматривается цепочка PREROUTING
- Просматривается таблица raw
- Просматривается таблица mangle, далее происходит отслеживание соединений
- Просматривается таблица nat (используется для DNAT - модификация адреса получателя)
- маршрутизация: если пакет надо маршрутизовать мимо локального хоста, то переходим к обработке проходящего пакета, если для он предназначен локальному хосту, то обрабатывается как локальный
- Просматривается цепочка INPUT
- Просматривается таблица mangle
- Просматривается таблица filter
Последовательность обработки пакета, уходящего с нашего хоста:
- Маршрутизация: определение исходящего адреса, адреса назначения, используемого интерфейса; если пакет маршрутизируется внутрь, то переходим к предыдущей процедуре
- Просматривается цепочка OUTPUT
- Просматривается таблица raw
- Просматривается таблица mangle, фильтровать здесь не стоит, здесь же происходит отслеживание локально создаваемых соединений
- Просматривается таблица nat (NAT для локально сгенерированных пакетов)
- Просматривается таблица filter
- Повторная маршрутизация, т.к. в таблицах mangle и nat пакет мог быть изменён; если пакет маршрутизируется внутрь, то переходим к предыдущей процедуре
- Просматривается цепочка POSTROUTING
- Просматривается таблица mangle
- Просматривается таблица nat (используется для SNAT - модификация адреса источника, фильтровать здесь не стоит)
Последовательность обработки проходящего пакета (начинается от п.2 первой процедуры):
- Просматривается цепочка FORWARD
- Просматривается таблица mangle
- Просматривается таблица filter
- повторная маршрутизация, т.к. в таблице mangle пакет мог быть изменён; если пакет маршрутизируется внутрь, то переходим к первой процедуре
- Просматривается цепочка POSTROUTING
- Просматривается таблица mangle
- Просматривается таблица nat (используется для SNAT и Masquerading, фильтровать здесь не стоит)
Как видно, таблица nat и mangle может модифицировать получателя или отправителя сетевого пакета. Именно поэтому сетевой пакет несколько раз сверяется с таблицей маршрутизации.
Механизм определения состояний (conntrack)
Выше в тексте несколько раз указывалось понятие "определение состояний", оно заслуживает отдельной темы для обсуждения, но тем не менее я кратко затрону данный вопрос в текущем посте. В общем, механизм определения состояний (он же state machine, он же connection tracking, он же conntrack) является частью пакетного фильтра и позволяет определить определить к какому соединению/сеансу принадлежит пакет. Conntrack анализирует состояние всех пакетов, кроме тех, которые помечены как NOTRACK в таблице raw. На основе этого состояния определяется принадлежит пакет новому соединению (состояние NEW), уже установленному соединению (состояние ESTABLISHED), дополнительному к уже существующему (RELATED), либо к "другому" (неопределяемому) соединению (состояние INVALID). Состояние пакета определяется на основе анализа заголовков передаваемого TCP-пакета. Модуль conntrack позволяет реализовать межсетевой экран сеансового уровня (пятого уровня модели OSI). Для управления данным механизмом используется утилита conntrack, а так же параметр утилиты iptables: -m conntrack или -m state (устарел). Состояния текущих соединений conntrack хранит в ядре. Их можно просмотреть в файле /proc/net/nf_conntrack (или /proc/net/ip_conntrack).
Чтобы мысли не превратились в кашу, думаю данной краткой информации для понимания дальнейшего материала будет достаточно.
Управление правилами сетевой фильтрации Netfilter (использование команды iptables)
Утилита iptables является интерфейсом для управления сетевым экраном netfilter. Данная команда позволяет редактировать правила таблиц, таблицы и цепочки. Как я уже говорил - каждое правило представляет собой запись/строку, содержащую в себе критерии отбора сетевых пакетов и действие над пакетами, которые соответствуют заданному правилу. Команда iptables требует для своей работы прав root.
В общем случае формат команды следующий:
iptables [-t таблица] команда [критерии] [действие]
Все параметры в квадратных скобках - необязательны. По умолчанию используется таблица filter, если же необходимо указать другую таблицу, то следует использовать ключ -t с указанием имени таблицы. После имени таблицы указывается команда, определяющая действие (например: вставить правило, или добавить правило в конец цепочки, или удалить правило). "критерии" задает параметры отбора. "действие" указывает, какое действие должно быть выполнено при условии совпадения критериев отбора в правиле (например: передать пакет в другую цепочку правил, "сбросить" пакет, выдать на источник сообщение об ошибке...).
Ниже приведены команды и параметры утилиты iptables:
|
Параметр |
Описание |
Пример |
|
Команды |
||
|
--append (-A) |
Добавить в указанную цепочку и указанную таблицу заданное правило в КОНЕЦ списка. |
iptables -A FORWARD критерии -j действие |
|
--delete (-D) |
Удаляет заданное номером(ами) или правилом(ами) правило(а). Первый пример удаляет все правила с номерами 10,12 во всех цепочках, в таблицах filter, второй пример удаляет заданное правило из таблицы mangle в цепочке PREROUTING. |
iptables -D 10,12 |
|
--rename-chain (-E) |
Изменить имя цепочки. |
iptables -E OLD_CHAIN NEW_CHAIN |
|
--flush (-F) |
Очистка всех правил текущей таблицы. Ко всем пакетам, которые относятся к уже установленным соединениям, применяем терминальное действие ACCEPT — пропустить |
iptables -F |
|
--insert (-I) |
Вставляет заданное правило в место, заданное номером. |
iptables -I FORWARD 5 критерии -j действие |
|
--list (сокр. -L) |
Просмотр существующих правил (без явного указания таблицы - отображается таблица filter всех цепочек). |
iptables -L |
|
--policy (-P) |
Устанавливает стандартную политику для заданной цепочки. |
iptables -t mangle -P PREROUTING DROP |
|
--replace (-R) |
Заменяет заданное номером правило на заданное в критериях. |
iptables -R POSROUTING 7 | критерии -j действие |
|
--delete-chain (-X) |
Удалить ВСЕ созданные вручную цепочки (оставить только стандартные INPUT, OUTPUT, FORWARD, PREROUTING и POSTROUTING). |
iptables -X |
|
--zero (-Z) |
Обнуляет счетчики переданных данных в цепочке. |
iptables -Z INPUT |
|
Параметры |
||
|
--numeric (-n) |
Не резолвит адреса и протоколы при выводе. |
|
|
--line-numbers |
Указывать номера правил при выводе (может использоваться совместно с -L). |
iptables -L --line-numbers |
|
--help (-h) |
куда же без нее |
|
|
-t таблица |
Задает название таблицы, над которой необходимо совершить действие. В примере сбрасывается таблица nat во всех цепочках. |
iptables -t nat -F |
|
--verbose (-v) |
Детальный вывод. |
iptables -L -v |
Критерии (параметры) отбора сетевых пакетов команды iptables
Критерии отбора сетевых пакетов негласно делятся на несколько групп: Общие критерии, Неявные критерии, Явные критерии. Общие критерии допустимо употреблять в любых правилах, они не зависят от типа протокола и не требуют подгрузки модулей расширения. Неявные критерии (я бы из назвал необщие), те критерии, которые подгружаются неявно и становятся доступны, например при указании общего критерия --protocol tcp|udp|icmp. Перед использованием Явных критериев, необходимо подключить дополнительное расширение (это своеобразные плагины для netfilter). Дополнительные расширения подгружаются с помощью параметра -m или --match. Так, например, если мы собираемся использовать критерии state, то мы должны явно указать это в строке правила: -m state левее используемого критерия. Отличие между явными и неявными необщими критериями заключается в том, что явные нужно подгружать явно, а неявные подгружаются автоматически.
Во всех критериях можно использовать знак ! перед значением критерия. Это будет означать, что под данное правило подпадают все пакеты, которые не соответствуют данному параметру. Например: критерий --protocol ! tcp будет обозначать, что все пакеты, которые не являются TCP-протоколом подходят под действие правила. Однако последние версии iptables (в частности, 1.4.3.2 и выше), уже не поддерживают этот синтаксис и требуют использования не --protocol ! tcp, а ! --protocol tcp, выдавая следующую ошибку:
Using intrapositioned negation (`--option ! this`) is deprecated in favor of extrapositioned (`! --option this`).
Ниже в виде таблицы приведены часто используемые параметры отбора пакетов:
|
Параметр |
Описание |
Пример |
|
--protocol |
Определяет протокол транспортного уровня. Опции tcp, udp, icmp, all или любой другой протокол определенный в /etc/protocols |
iptables -A INPUT -p tcp |
|
--source |
IP адрес источника пакета. Может быть определен несколькими путями:
Настойчиво не рекомендуется использовать доменные имена, для разрешения (резольва) которых требуются DNS-запросы, так как на этапе конфигурирования netfilter DNS может работать некорректно. Также, заметим, имена резольвятся всего один раз — при добавлении правила в цепочку. Впоследствии соответствующий этому имени IP-адрес может измениться, но на уже записанные правила это никак не повлияет (в них останется старый адрес). Если указать доменное имя, которое резольвится в несколько IP-адресов, то для каждого адреса будет добавлено отдельное правило. |
iptables -A INPUT -s 10.10.10.3 |
|
--destination |
IP адрес назначения пакета. Может быть определен несколькими путями (см. --source). |
iptables -A INPUT --destination 192.168.1.0/24 |
|
--in-interface |
Определяет интерфейс, на который прибыл пакет. Полезно для NAT и машин с несколькими сетевыми интерфейсами. Применяется в цепочках INPUT, FORWARD и PREROUTING. Возможно использование знака "+", тогда подразумевается использование всех интерфейсов, начинающихся на имя+ (например eth+ - все интерфейсы eth). |
iptables -t nat -A PREROUTING --in-interface eth0 |
|
--out-interface |
Определяет интерфейс, с которого уйдет пакет. Полезно для NAT и машин с несколькими сетевыми интерфейсами. Применяется в цепочках OUTPUT, FORWARD и POSTROUTING. Возможно использование знака "+". |
iptables -t nat -A POSTROUTING --in-interface eth1 |
|
-p proto -h |
вывод справки по неявным параметрам протокола proto. |
iptables -p icmp -h |
|
--source-port |
Порт источник, возможно только для протоколов --protocol tcp, или --protocol udp |
iptables -A INPUT --protocol tcp --source-port 25 |
|
--destination-port |
Порт назначения, возможно только для протоколов --protocol tcp, или --protemocol udp |
iptables -A INPUT --protocol udp --destination-port 67 |
|
-m state --state (устарел) |
Состояние соединения. Доступные опции:
|
iptables -A INPUT -m state --state NEW,ESTABLISHEDiptables -A INPUT -m conntrack --ctstate NEW,ESTABLISHED |
|
-m mac --mac-source |
Задает MAC адрес сетевого узла, передавшего пакет. MAC адрес должен указываться в форме XX:XX:XX:XX:XX:XX. |
-m mac --mac-source 00:00:00:00:00:0 |
Действия над пакетами
Данный заголовок правильнее будет перефразировать в "Действия над пакетами, которые совпали с критериями отбора". Итак, для совершения какого-либо действия над пакетами, необходимо задать ключ -j (--jump) и указать, какое конкретно действие совершить.
Действия над пакетами могут принимать следующие значения:
- ACCEPT - пакет покидает данную цепочку и передается в следующую (дословно - ПРИНЯТЬ).
- DROP - отбросить удовлетворяющий условию пакет, при этом пакет не передается в другие таблицы/цепочки.
- REJECT - отбросить пакет, отправив отправителю ICMP-сообщение, при этом пакет не передается в другие таблицы/цепочки.
- RETURN - возвратить пакет в предыдущую цепочку и продолжить ее прохождение начиная со следующего правила.
- SNAT - применить трансляцию адреса источника в пакете. Может использоваться только в цепочках POSTROUTING и OUTPUT в таблицах nat.
- DNAT - применить трансляцию адреса назначения в пакете. Может использоваться в цепочке PREROUTING в таблице nat. (в исключительных случаях - в цепочке OUTPUT)
- LOG - протоколировать пакет (отправляется демону syslog) и обработать остальными правилами.
- MASQUERADE — используется вместо SNAT при наличии соединения с динамическим IP (допускается указывать только в цепочке POSTROUTING таблицы nat).
- MARK — используется для установки меток на пакеты, передается для обработки дальнейшим правилам.
- и др.
Кроме указанных действий, существуют и другие, с которыми можно ознакомиться в документации (возможно, в скором времени я дополню статью в ходе освоения темы). У некоторых действий есть дополнительные параметры.
В таблице ниже приведены примеры и описания дополнительных параметров:
|
Параметр |
Описание |
Пример |
|
DNAT (Destination Network Address Translation) |
||
|
--to-destination |
указывает, какой IP адрес должен быть подставлен в качестве адреса места назначения. В примере во всех пакетах протокола tcp, пришедших на адрес 1.2.3.4, данный адрес будет заменен на 4.3.2.1. |
iptables -t nat -A PREROUTING -p tcp -d 1.2.3.4 -j DNAT --to-destination 4.3.2.1 |
|
LOG |
||
|
--log-level |
Используется для задания уровня журналирования (log level). В примере установлен максимальный уровень логирования для всех tcp пакетов в таблице filter цепочки FORWARD. |
iptables -A FORWARD -p tcp -j LOG --log-level debug |
|
--log-prefix |
Задает текст (префикс), которым будут предваряться все сообщения iptables. (очень удобно для дальнейшего парсинга) Префикс может содержать до 29 символов, включая и пробелы. В примере отправляются в syslog все tcp пакеты в таблице filter цепочки INPUT с префиксом INRUT-filter. |
iptables -A INPUT -p tcp -j LOG --log-prefix "INRUT-filter" |
|
--log-ip-options |
Позволяет заносить в системный журнал различные сведения из заголовка IP пакета. |
iptables -A FORWARD -p tcp -j LOG --log-ip-options |
|
и др... |
|
|
На этом закончим теорию о сетевом фильтре netfilter/iptables. В следующей статье я приведу практические примеры для усвоения данной теории.
Резюме
В данной статье мы рассмотрели очень кратко основные понятия сетевого фильтра в Linux. Итак, подсистема netfilter/iptables является частью ядра Linux и используется для организации различных схем фильтрации и манипуляции с сетевыми пакетами. При этом, каждый пакет проходит от сетевого интерфейса, в который он прибыл и далее по определенному маршруту цепочек, в зависимости от того, предназначен он локальной системе или "нелокальной". Каждая цепочка состоит из набора таблиц, содержащих последовательный набор правил. Каждое правило состоит из определенного критерия/критериев отбора сетевого пакета и какого-то действия с пакетом, соответствующего данным критериям. В соответствии с заданными правилами над пакетом может быть совершено какое-либо действие (Например, передача следующей/другой цепочке, сброс пакета, модификация содержимого или заголовков и др.). Каждая цепочка и каждая таблица имеет свое назначение, функциональность и место в пути следования пакета. Например для фильтрации пакетов используется таблица filter, которая содержится в трех стандартных цепочках и может содержаться в цепочках, заданных пользователем. Завершается путь пакета либо в выходящем сетевом интерфейсе, либо доставкой локальному процессу/приложению.
Литература
Довольно много интересной информации на русском содержится тут:
- http://www.opennet.ru/docs/RUS/iptables/
- http://ru.wikibooks.org/wiki/Iptables
Более глубоко материал доступен на буржуйском вот тут:
- http://www.frozentux.net/documents/ipsysctl-tutorial/
- http://www.netfilter.org/documentation/index.html
- Подробности
- Автор: Super User
- Категория: Linux
- Просмотров: 3474
Надоели разнообразные хакеры пытающиеся сломать админку и раздувающие логи апача. Ограничил доступ при помощи htaccess
добавил в директории к которым ограничен доступ файл .htaccess со следующей конструкцией
<Limit GET POST>
Order Deny,Allow
Deny from all
Allow from 192.168.1.1
Allow from xxx.xxx.xxx.xxx
Allow from yy.yyy.yyy.yy
и так далее
</Limit>
встречался с конструкцией Allow from 192.168.1.1, xx.xxx.xxx.xxx, yy.yyy.yyy.yy но у меня отрабатывался только последний адрес в строке, так что каждый адрес в отдельной строке.
если например надо указать всю 10.100.5.0/24 подсеть то делается так 10.100.5
- Подробности
- Автор: Super User
- Категория: Linux
- Просмотров: 16249
Доброго времени, уважаемые гости и читатели Блога любителя экспериментов. Сегодня хочу затронуть такой вопрос, как управление сетевой подсистемой Linux с помощью программ из пакета iproute2. Для понимания того, о чем здесь пойдет речь обязательно необходимо ознакомиться со статьями Основные понятия сетей и Настройка сети в Linux, диагностика и мониторинг. Начну с небольшой предыстории...
Думаю, очень к месту будет напомнить о модели OSI, ибо с ней (с моделью OSI) в статье будет тесное взаимодействие. Поэтому привожу картинки из статьи. В Linux статическая конфигурация сети настраивается с помощью конфигурационных файлов. Данный способ настройки я рассматривал в статье Настройка сети в Linux, диагностика и мониторинг.
В старых версиях ядер Linux (2.4 и ниже) существовали инструменты настройки сети из пакета net-tools, которые включали в себя такие команды, как ifconfig - для управления сетевыми интерфейсами, route - управление таблицей маршрутизации, arp - управление таблицей разрешения имен, netstat - сетевая статистика, mii-tool - статус сетевых устройств и др. В дистрибутивах, использующих современные ядра внедряется пакет iproute2 (иногда называется iproute) и net-tools оставлен, как некоторые утверждают, для совместимости. В пакет iproute входят 3 основных утилиты: ip - команда для просмотра параметров и настройки сетевых интерфейсов, IP-адресов, таблиц маршрутизации, правил маршрутизации, таблиц ARP преобразования, IP-туннелей и т.д. tc (traffic control) - команда для просмотра и настройки параметров управления трафиком (классификация трафика, дисциплины управления очереди для различных классов трафика), ss - команда для просмотра текущих соединений и открытых портов (аналог netstat).
Управление сетевыми интерфейсами в Linux
Сетевые интерфейсы в линух представляют собой физические устройства, которые взаимодействуют с ядром, а деле и с пользователем через соответствующий драйвер (например Ethernet-драйвера именуют интерфейсы как eth0, eth1 ...). Чтобы сетевой интерфейс функционировал, на нем нужно задать настройки какого-либо протокола сетевого уровня (IP, IPX или др.). В современных сетях используется протокол IP. Для управления сетью используется команда ip. Давайте рассмотрим общие параметры команды ip, данные параметры отлично иллюстрирует википедия:
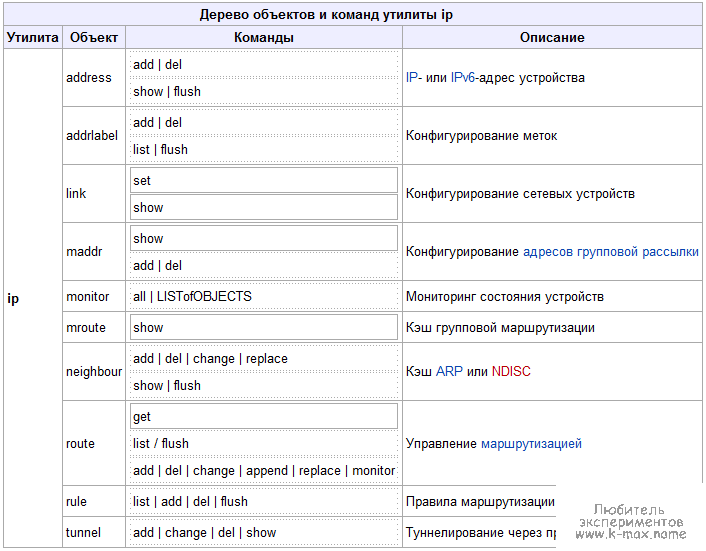
Настройка параметров сетевых интерфейсов
Давайте разберем некоторые аспекты данных команд. Начнем с аналога команды ifconfig - команда ip с параметром link управляет свойствами сетевого интерфейса:
[proxy ~]# ip link show
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 16436 qdisc noqueue state UNKNOWN
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc mq state UP
qlen 1000 link/ether 00:1d:72:01:ab:93 brd ff:ff:ff:ff:ff:ff
3: irda0: <NOARP> mtu 2048 qdisc noop state DOWN qlen 8
link/irda 00:00:00:00 brd ff:ff:ff:ff
4: vboxnet0: <BROADCAST,MULTICAST> mtu 1500 qdisc noop state DOWN qlen 1000
link/ether 0a:00:27:00:00:00 brd ff:ff:ff:ff:ff:ff
5: ppp0: <POINTOPOINT,MULTICAST,NOARP,UP,LOWER_UP> mtu 1400 qdisc pfifo_fast state UNKNOWN qlen 3
link/ppp
Вывод данной команды содержит пронумерованный список интерфейсов, присутствующих в системе. Информация об интерфейсе содержит две строки: в первой указывается имя интерфейса (lo, eth0 и др.), установленные флаги состояния (в фигурных скобках < и >), MTU (Maximum Transmission Unit, максимально допустимый размер фрейма в байтах), тип и размер очереди фреймов; во второй строке — тип соединения, MAC-адрес, широковещательный адрес и т. п.
Некоторые флаги состояния:
- UP — устройство подключено и готово принимать и отправлять фреймы;
- LOOPBACK — интерфейс является локальным и не может взаимодействовать с другими узлами в сети;
- BROADCAST - устройство способно отправлять широковещательные фреймы;
- POINTTOPOINT — соединение типа "точка-точка"
- PROMISC — устройство находится в режиме "прослушивания" и принимает все фреймы.
- NOARP — отключена поддержка разрешения имен сетевого уровня.
- ALLMULTI — устройство принимает все групповые пакеты.
- NO-CARRIER — нет связи (не подключен кабель).
- DOWN — устройство отключено.
Можно также вывести информацию о выбранном интерфейсе, задав его имя в параметре dev:
[proxy ~]# ip link show dev eth0
или просто:
[proxy ~]# ip link show eth0
Команда ip link также позволяет изменять свойства сетевого интерфейса. Для этого используется параметр set:
iproute:~# ip link show dev eth2
3: eth2: <BROADCAST,MULTICAST> mtu 1500 qdisc noop state DOWN qlen 1000
link/ether 08:00:27:c9:00:f0 brd ff:ff:ff:ff:ff:ff
iproute:~# # установка значения MTU
iproute:~# ip link set mtu 1400 eth2
iproute:~# # установка MAC адреса
iproute:~# ip link set address 00:11:11:12:FE:09 eth2
iproute:~# # "поднятие" интерфейса
iproute:~# ip link set up eth2
iproute:~# ip link show dev eth2
3: eth2: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1400 qdisc pfifo_fast state UP qlen 1000
link/ether 00:11:11:12:fe:09 brd ff:ff:ff:ff:ff:ff
iproute:~# # отключение интерфейса
iproute:~# ip link set down eth2
iproute:~# ip link show dev eth2
3: eth2: <BROADCAST,MULTICAST> mtu 1400 qdisc pfifo_fast state DOWN qlen 1000
link/ether 00:11:11:12:fe:09 brd ff:ff:ff:ff:ff:ff
Указанные тут команды являются аналогами "классических" команд из пакета net-tools:
# ifconfig eth2 mtu 1400
# ifconfig eth2 hw ether 00:11:12:13:14:15
# ifconfig eth2 up
# ifconfig eth2 down
Управление физическими параметрами интерфейса
Физические параметры (скорость, технология Ethernet, тип дуплекса) сетевого подключения зависят от используемого оборудования и обычно настраиваются автоматически при подключении компьютера к сети. Но иногда из- за несогласованной работы оборудования и драйверов адаптера параметры необходимо выставить вручную, используя утилиту ethtool. Данная утилита включена в стандартные репозитории Debian и устанавливается из пакетного менеджера. Пример использования утилиты:
iproute:~# ethtool eth2
Settings for eth2:
Supported ports: [ TP ]
Supported link modes: 10baseT/Half 10baseT/Full
100baseT/Half 100baseT/Full
1000baseT/Full
Supports auto-negotiation: Yes
Advertised link modes: 10baseT/Half 10baseT/Full
100baseT/Half 100baseT/Full
1000baseT/Full
Advertised pause frame use: No
Advertised auto-negotiation: Yes
Speed: 1000Mb/s
Duplex: Full
Port: Twisted Pair
PHYAD: 0
Transceiver: internal
Auto-negotiation: on
MDI-X: Unknown
Supports Wake-on: umbg
Wake-on: d
Current message level: 0x00000007 (7)
Link detected: no
iproute:~# ethtool -i eth2
driver: e1000
version: 7.3.21-k5-NAPI
firmware-version: N/A
bus-info: 0000:00:08.0
Настройка параметров сетевых протоколов на физическом интерфейсе
Напомню, что протокол IP является маршрутизируемым протоколом без установления соединения. IP адрес представляет собой комбинацию номера сети и номера узла в данной сети. Количество бит, используемых для номера сети определяется по классу адреса или задается маской подсети. Итого, как я уже говорил, чтобы сетевой интерфейс начал функционировать в соответствии со своим прямым назначением, необходимо на нем задать параметры соответствующего сетевого протокола. Для протокола IP минимально необходимые параметры - это IP адрес и маска подсети. Для настройки параметров протокола IP на сетевом интерфейсе с помощью командной строки необходимо использовать команду ip address (она же ip addr).
user@nout:~$ ip addr show
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 16436 qdisc noqueue state UNKNOWN
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
2: eth0: <NO-CARRIER,BROADCAST,MULTICAST,UP> mtu 1500 qdisc pfifo_fast state DOWN qlen 1000
link/ether 90:e6:ba:2f:c1:d4 brd ff:ff:ff:ff:ff:ff
3: wlan0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc mq state UP qlen 1000
link/ether 00:25:d3:3f:3e:87 brd ff:ff:ff:ff:ff:ff
inet 192.168.1.148/24 brd 192.168.1.255 scope global wlan0
inet6 fe80::225:d3ff:fe3f:3e87/64 scope link
valid_lft forever preferred_lft forever
Параметр show отображает текущую конфигурацию. Каждая запись о сетевом адресе может содержать информацию о типе адреса (inet — адрес IPv4, inet6 — IPv6 и т. д.), непосредственно адрес, маску подсети (количество сетевых бит), широковещательный адрес данной сети, область видимости (scope global — действителен везде, scope link — только для данного устройства, scope host — для данного узла, доступные области приведены в /etc/iproute2/rt_scopes) и имя логического интерфейса.
user@nout:~$ # добавление адреса выполняется параметром add
user@nout:~$ # при этом необходимо задать широковещательный адреc
user@nout:~$ # (параметр brd + задает автоматический рассчет широковещательного адреса)
user@nout:~$ # данная операция требует прав суперпользователя
user@nout:~$ ip address add 192.168.1.3/25 brd + dev eth0
RTNETLINK answers: Operation not permitted
user@nout:~$ sudo -s
[sudo] password for user:
nout:~# ip address add 192.168.1.3/25 brd + dev eth0
nout:~# ip address show dev eth0
2: eth0: <NO-CARRIER,BROADCAST,MULTICAST,UP> mtu 1500 qdisc pfifo_fast state DOWN qlen 1000
link/ether 90:e6:ba:2f:c1:d4 brd ff:ff:ff:ff:ff:ff
inet 192.168.1.3/25 brd 192.168.1.127 scope global eth0
nout:~# # удаление адреса производится параметром del
nout:~# ip address del 192.168.1.3/25 dev eth0
nout:~# ip address show dev eth0
2: eth0: <NO-CARRIER,BROADCAST,MULTICAST,UP> mtu 1500 qdisc pfifo_fast state DOWN qlen 1000
link/ether 90:e6:ba:2f:c1:d4 brd ff:ff:ff:ff:ff:ff
C помощью ip можно задать несколько IP адресов на одном интерфейсе:
nout:~# ip address add 192.168.1.11/25 brd + dev eth0
nout:~# ip address add 192.168.1.12/25 brd + dev eth0
nout:~# ip address show dev eth0
2: eth0: <NO-CARRIER,BROADCAST,MULTICAST,UP> mtu 1500 qdisc pfifo_fast state DOWN qlen 1000
link/ether 90:e6:ba:2f:c1:d4 brd ff:ff:ff:ff:ff:ff
inet 192.168.1.11/25 brd 192.168.1.127 scope global eth0
inet 192.168.1.12/25 brd 192.168.1.127 scope global secondary eth0
nout:~# ip address del 192.168.1.11/25 dev eth0
nout:~# ip address show dev eth0
2: eth0: <NO-CARRIER,BROADCAST,MULTICAST,UP> mtu 1500 qdisc pfifo_fast state DOWN qlen 1000
link/ether 90:e6:ba:2f:c1:d4 brd ff:ff:ff:ff:ff:ff
nout:~# ip address add 192.168.1.12/25 brd + dev eth0
nout:~# ip address add 192.168.1.212/25 brd + dev eth0
nout:~# ip address show dev eth0
2: eth0: <NO-CARRIER,BROADCAST,MULTICAST,UP> mtu 1500 qdisc pfifo_fast state DOWN qlen 1000
link/ether 90:e6:ba:2f:c1:d4 brd ff:ff:ff:ff:ff:ff
inet 192.168.1.12/25 brd 192.168.1.127 scope global eth0
inet 192.168.1.212/25 brd 192.168.1.255 scope global eth0
При добавлении адреса из той же сети, что и существующий, новый адрес становится дополнительным к существующему (secondary), и если удалить основной адрес, то будет удален и дополнительный. При этом, команда ifconfig не умеет отображать второй Ip:
nout:~# ifconfig eth0
eth0 Link encap:Ethernet HWaddr 90:e6:ba:2f:c1:d4
inet addr:192.168.1.12 Bcast:192.168.1.127 Mask:255.255.255.128
UP BROADCAST MULTICAST MTU:1500 Metric:1
RX packets:0 errors:0 dropped:0 overruns:0 frame:0
TX packets:0 errors:0 dropped:0 overruns:0 carrier:1
collisions:0 txqueuelen:1000
RX bytes:0 (0.0 B) TX bytes:0 (0.0 B)
Interrupt:43
Возможно создать ifconfig - совместимую реализацию способа использования нескольких IP-адресов на одном сетевом интерфейсе. Для этого следует в команде ip addr add использовать параметр label:
nout:~# ip address add 192.168.12.212/25 brd + dev eth0 label eth0:newdev
nout:~# ifconfig
eth0 Link encap:Ethernet HWaddr 90:e6:ba:2f:c1:d4
inet addr:192.168.1.12 Bcast:192.168.1.127 Mask:255.255.255.128
UP BROADCAST MULTICAST MTU:1500 Metric:1
RX packets:0 errors:0 dropped:0 overruns:0 frame:0
TX packets:0 errors:0 dropped:0 overruns:0 carrier:1
collisions:0 txqueuelen:1000
RX bytes:0 (0.0 B) TX bytes:0 (0.0 B)
Interrupt:43
eth0:newdev Link encap:Ethernet HWaddr 90:e6:ba:2f:c1:d4
inet addr:192.168.12.212 Bcast:192.168.12.255 Mask:255.255.255.128
UP BROADCAST MULTICAST MTU:1500 Metric:1
Interrupt:43
nout:~# ip address show dev eth0
2: eth0: <NO-CARRIER,BROADCAST,MULTICAST,UP> mtu 1500 qdisc pfifo_fast state DOWN qlen 1000
link/ether 90:e6:ba:2f:c1:d4 brd ff:ff:ff:ff:ff:ff
inet 192.168.1.12/25 brd 192.168.1.127 scope global eth0
inet 192.168.1.212/25 brd 192.168.1.255 scope global eth0
inet 192.168.12.212/25 brd 192.168.12.255 scope global eth0:newdev
nout:~# ip address flush dev eth0
nout:~# ip address show dev eth0
2: eth0: <NO-CARRIER,BROADCAST,MULTICAST,UP> mtu 1500 qdisc pfifo_fast state DOWN qlen 1000
link/ether 90:e6:ba:2f:c1:d4 brd ff:ff:ff:ff:ff:ff
Как видно, параметр flush очищает все установленные на интерфейсе IP адреса.
Управление ARP-таблицей
В локальной сети текущий хост для определения физических адресов (MAC-адресов) по IP-адресам удаленных узлов использует протокол ARP и локальный ARP -кэш (ARP-таблицу). Управление ARP-таблицей осуществляется командой ip neigh. Каждый узел локальной сети (в том числе и хабы/свичи) содержат свою локальную ARP-таблицу (кэш), которая устанавливает соответствие между IP и MAC-адресами узлов подсетей, в которые входит данную сеть. В ARP-таблице имеются два вида записей:
- Динамические записи, которые периодически обновляются с использованием протокола ARP (если запись "устаревает", то она удаляется).
- Статические записи, которые создаются пользователем с помощью соответствующих команд и существуют до тех пор, пока текущий узел не будет выключен/перезагружен.
nout:~# # отображение содержимого таблицы ARP
nout:~# ip neigh show
192.168.1.1 dev wlan0 lladdr bc:ae:c5:c3:c9:31 REACHABLE
nout:~# # добавление статической записи в ARP таблицу
nout:~# ip neigh add 192.168.1.100 lladdr 00:00:00:11:00:22 dev wlan0
nout:~# ip neigh show
192.168.1.100 dev wlan0 lladdr 00:00:00:11:00:22 PERMANENT
192.168.1.1 dev wlan0 lladdr bc:ae:c5:c3:c9:31 REACHABLE
nout:~# # удаление записи
nout:~# ip neigh del 192.168.1.100 dev wlan0
nout:~# ip neigh show
192.168.1.1 dev wlan0 lladdr bc:ae:c5:c3:c9:31 REACHABLE
Управление маршрутизацией с помощью iproute2
Из статьи Основные понятия сетей мы знаем, что если текущему узлу необходимо куда-либо отправить IP пакет, то сетевая подсистема ядра использует таблицу маршрутизации. Если пакет отправляется в ту же подсеть, которой принадлежит хост, то с помощью ARP определяется физический адрес хоста назначения и пакет отправляется напрямую хосту назначения. Если адрес назначения принадлежит не "локальной сети", то пакет отправляется на шлюз (читай - направляется по маршруту), который указан в таблице маршрутизации для сети, которой принадлежит хост назначения. При этом, выбирается та сеть, в которой адрес сети наиболее заполнен (читай - меньше хостов в подсети). Если для хоста назначения не найден маршрут, то пакет отправляется на "шлюз по умолчанию". Все шлюзы должны находиться в той же подсети, что и исходный хост.
Допустим, в локальной сети есть некоторый хост с адресом 192.168.1.100/24, а так же есть хост 192.168.1.1, который является шлюзом в глобальную сеть, а так же есть хост с адресом 192.168.1.2, который является связующим маршрутизатором с сетью 192.168.24.0/24. Для того, чтобы хост с адресом 192.168.1.100/24 имел доступ в сеть Интернет и к локальной сети 192.168.24.0/24, необходимо внести в таблицу маршрутизации соответствующие записи, например с помощью команды ip route add:
# ip route add default via 192.168.1.1
# ip route add 192.168.24.0/24 via 192.168.1.2
# ip route show
192.168.1.0/24 dev eth1 proto kernel scope link src 192.168.1.100
192.168.24.0/24 via 192.168.1.2 dev eth1
default via 192.168.1.1 dev eth
Первая команда добавляет маршрут по умолчанию (default) через узел 192.168.1.1 (параметр via ). Вторая команда устанавливает маршрут на сеть 192.168.24.0/24 через узел 192.168.1.2.
Для вывода на экран содержимого таблицы маршрутизации используется команда ip route show. В данном случае в таблице маршрутизации три записи: первая о том, что сеть 192.168.1.0/24 доступна непосредственно на интерфейсе eth1 (запись добавляется автоматически), и две записи, добавленные пользователем: альтернативный маршрут и маршрут по умолчанию.
Добавление постоянного статического маршрута при инициализации сети
О настройке сети через конфигурационные файлы я рассказывал в статье Настройка сети в Linux, диагностика и мониторинг, в сегодняшней статье я немного дополню эту информацию. С помощью файла /etc/network/interfaces есть возможность задать постоянные маршрута при поднятии интерфейса и удаление маршрута при выключении интерфейса. Это делается с помощью параметра up и down соответственно. Нижеприведенная конфигурация позволяет задать маршрут до сети 192.168.100.0/24 через шлюз 192.168.1.1:
iface eth1 inet static
address 192.168.1.100
netmask 255.255.255.0
up ip route add 192.168.100.0/24 via 192.168.1.1
down ip route del 192.168.100.0/24
gateway 192.168.1.3
Выводы
На этом, данную заметку заканчиваю. Подведу краткие итоги. Для управления физическими интерфейсами применяется команда ip link из пакета iproute. Для настройки свойств физического подключения (скорость, технология, тип дуплекса используется команда ethtool. Для того, чтобы хост мог взаимодействовать с другими узлами подсети в рамках локального сегмента (широковещательного домена) на нем должен быть установлен IP-адрес и определена маска подсети. Для управления IP-адресами в Linux можно использовать команду ip addr. В локальной сети данный узел для определения физических адресов(MAC) по IP - адресам других узлов использует протокол ARP и локальный ARP -кэш (таблица). Управление ARP -таблицей осуществляется командой ip neigh. Для взаимодействия с удаленными подсетями на данном узле необходимо определить шлюз по умолчанию или/и альтернативные шлюзы. Все шлюзы должны находиться в той же подсети, что и исходный узел. Управление таблицей маршрутизации на узле может осуществляться командой ip route. У параметров команд пакета iproute2 есть сокращенный синтаксис, например, ip link show eth0 можно записать как ip l sh eth0.
- Подробности
- Автор: Super User
- Категория: Linux
- Просмотров: 8321
оригинал тут - http://www.k-max.name/linux/ntp-server-na-linux/
скопировал себе что бы не искать
Протокол NTP
Network Time Protocol (NTP) — сетевой протокол для синхронизации внутренних часов компьютера с использованием сетей с переменной латентностью (читай "шириной"/качеством канала).
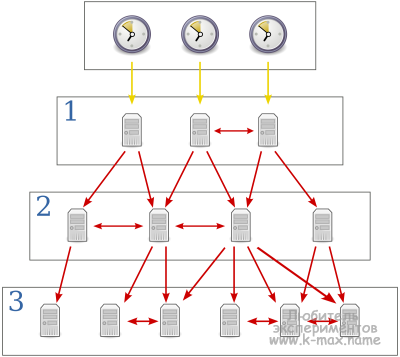
NTP использует для своей работы протокол UDP и порт 123.
Текущая версия протокола — NTP 4. NTP использует иерархическую систему «часовых уровней» (их так же называют Stratum). Уровень 0 (или Stratum 0) - это, обычно, устройства представляющие собой атомные часы (молекулярные, квантовые), GPS часы или радиочасы. Данные устройства обычно не публикуются во всемирную сеть, а подключаются напрямую к серверам времени уровня 1 посредством протокола RS-232 (на иллюстрации обозначены желтыми стрелками). Уровень 1 синхронизирован с высокоточными часами уровня 0, обычно работают в качестве источников для серверов уровня 2. Уровень 2 синхронизируется с одной из машин уровня 1, а так же возможна синхронизация с серверами своего уровня. Уровень 3 работает аналогично второму. Обычно в сеть публикуются сервера уровней от второго и ниже. Протокол NTP поддерживает до 256 уровней. Так же хочется отметить, что сервера уровней 1 и2, а иногда и 3 не всегда открыты для всеобщего доступа. Иногда, чтобы синхронизироваться с ними, необходимо послать запрос по почте - администраторам домена.
Для чего делается ограничение на доступ к серверам? С переходом на каждый уровень немного возрастает погрешность относительно первичного сервера, но зато увеличивается общее число серверов и, следовательно, уменьшается их загрузка.
Назначение сервера NTP в локальной сети
Для чего нам может понадобиться NTP server? Например, существуют службы в операционных системах, которые могут зависеть от синхронизированного времени. Наиболее ярким примером таких служб является протокол аутентификации Kerberos. Для его работы необходимо, чтобы на компьютерах, доступ к которым осуществляется с использованием этого протокола, системное время различалось не более чем на 5 минут. Кроме того, точное время на всех компьютерах значительно облегчает анализ журналов безопасности при расследовании инцидентов в локальной сети.
Режимы работы NTP сервера/клиента
Клиент/сервер
Этот режим на сегодняшний день наиболее часто используется в сети Интернет. Схема работы – классическая. Клиент посылает запрос, на который в течение некоторого времени сервер присылает ответ. Настройка клиента производится с помощью директивы server в конфигурационном файле, где указывается DNS имя сервера времени.
Симметричный активный/пассивный режим
Этот режим используется в том случае, если производится синхронизация времени между большим количеством равноправных машин. Помимо того, что каждая машина синхронизируется с внешним источником, она также осуществляет синхронизацию со своими соседями (peer), выступая для них в качестве клиента и сервера времени. Поэтому даже если машина «потеряет» внешний источник, она все еще сможет получить точное время от своих соседей. Соседи могут работать в двух режимах – активном и пассивном. Работая в активном режиме, машина сама передает свое время всем машинам-соседям, перечисленным в секции peers конфигурационного файла ntp.conf. Если же в этой секции соседи не указаны, то считается, что машина работает в пассивном режиме. Для того чтобы злоумышленник не смог скомпрометировать другие машины, представившись в качестве активного источника, необходимо использовать аутентификацию.
Режим Broadcast
Этот режим рекомендуется использовать в тех случаях, когда малое количество серверов обслуживает большое количество клиентов. Работая в этом режиме, сервер периодически рассылает пакеты, используя широковещательный адрес подсети. Клиент, настроенный на синхронизацию таким способом, получает широковещательный пакет сервера и производит синхронизацию с сервером. Особенностью этого режима является то, что время доставляется в рамках одной подсети (ограничение broadcast-пакетов). Кроме того, для защиты от злоумышленников необходимо использовать аутентификацию.
Режим Multicast
Данный режим во многом похож на broadcast. Отличие заключается в том, что для доставки пакетов используются multicast-адреса сетей класса D адресного пространства IP-адресов. Для клиентов и серверов задается адрес multicast-группы, которую они используют для синхронизации времени. Это делает возможным синхронизацию групп машин, расположенных в различных подсетях, при условии, что соединяющие их маршрутизаторы поддерживают протокол IGMP и настроены на передачу группового трафика.
Режим Manycast
Этот режим является нововведением четвертой версии протокола NTP. Он подразумевает поиск клиентом среди своих сетевых соседей manycast-серверов, получение от каждого из них образцов времени (с использованием криптографии) и выбор на основании этих данных трех «лучших» manycast-серверов, с которыми клиент будет производить синхронизацию. В случае выхода из строя одного из серверов клиент автоматически обновляет свой список.
Для передачи образцов времени клиенты и серверы, работающие в manycast-режиме, используют адреса multicast-групп (сети класса D). Клиенты и серверы, использующие один и тот же адрес, формируют одну ассоциацию. Количество ассоциаций определяется количеством используемых multicast-адресов.
Время в Linux
Кратко расскажу, какое время существует в Linux и как его задать. В Linux, как и в другой ОС, существует 2 времени. Первые - аппаратные, иногда называемые Real Time Clock, сокращенно (RTC) (они же - часы BIOS) обычно они связаны с колеблющимся кварцевым кристаллом, имеющим точность хода до нескольких секунд в день. Точность зависит от различных колебаний, например, окружающей температуры. Вторые часы — внутренние программные часы, которые идут непрерывно, в том числе и при перерывах в работе системы. Они подвержены отклонениям, связанным с большой системной нагрузкой и задержкой прерываний. Однако система обычно считывает показания аппаратных часов при загрузке и потом использует системные часы.
Дата и время операционной системы устанавливается при загрузке на основании значения аппаратных часов, а так же настроек часового пояса. Настройки часового пояса берутся из файла /etc/localtime. Данный файл - есть ссылка (но чаще - копия) одного из файлов в структуре каталога /usr/share/zoneinfo/.
Аппаратные часы Linux могут хранить время в формате UTC (аналог GMT), либо текущее территориальное время. Общая рекомендация в том, какое время устанавливать (?) следующая: если на компьютере установлено несколько ОС и одна из них - Windows, то необходимо использовать текущее время (т.к. Windows берет время из BIOS/CMOS и считает его локальным). Если используются только операционные системы UNIX семейства, то желательно хранить время в BIOS в UTC формате.
После загрузки операционной системы, часы операционной системы и BIOS полностью независимы. Ядро системы раз в 11 секунд синхронизирует системные часы с аппаратными.
Через некоторое время между аппаратными и программными часами может быть разница в несколько секунд. Какие же часы содержат правильное время? Ни те, ни другие, пока мы не настроим синхронизацию времени.
Примечание:
Ядро Linux'а всегда хранит и вычисляет время, как число секунд прошедших с полночи 1-го января 1970 года, в независимости от того, установлены ваши часы на локальное или всемирное время. Преобразование в локальное время производится в процессе запроса.
Поскольку количество секунд с 1-го января 1970 года всемирного времени сохраняется как знаковое 32-битное целое (это справедливо для Linux/Intel систем), ваши часы перестанут работать где-то в 2038 году. Linux не имеет проблемы 2000-го года, но имеет проблему 2038 года. К счастью, к тому времени все linux'ы будут запущены на 64-х разрядных системах. 64-х битное целое будет содержать наши часы приблизительно до 292271-миллионного года.
NTP Server Linux
Введение
Существует масса реализаций для синхронизации времени для ОС Linux. Наиболее известными являются Xntpd (NTP версия 3), ntpd (NTP версия 4), Crony и ClockSpeed. В нашем примере мы будем использовать ntp-сервер ntpd.
Демон ntpd является одновременно и сервером времени и клиентом, в зависимости от настроек конфигурационного файла /etc/ntpd.conf (иногда /etc/ntp.conf), демон может и "принимать" время с уделенных серверов и "раздавать" другим хостам время.
Общая схема синхронизации времени в локальной сети следующая: необходимо иметь 1 или 2 сервера, имеющие доступ в глобальную сеть, которые будут получать время из интернет. Все компьютеры локальной сети синхронизировать с указанными серверами, получающими время из интернет.
Установка ntpd
Собственно, установка демона сводится к установке следующих пакетов: ntp (пакет включающий самого демона), ntpdate (утилита для ручной синхронизации времени - устарела), ntp-doc (документация по пакету), в некоторых дистрибутивах нужно будет установить так же ntp-utils (утилиты для диагностики), в некоторых они включены в пакет ntp. Как производить установку программ в Linux , я описывал в управление ПО Linux. После установки пакета, в большинстве дистрибутивов, демон будет уже сконфигурирован как как ntp-клиент (например в Debian было так). Соответственно, автоматически были созданы основные конфигурационные файлы: /etc/ntp.conf и /var/lib/ntp/ntp.drift и автоматом запущен демон.
Перед настройкой демона на синхронизацию с внешним миром я бы посоветовал установить текущую системную дату на значение, максимально приближенное к реальному времени. Установка даты в Linux производится командой: date MMDDhhmmCCYY.ss, где MM — месяц, DD — день месяца, hh — часы, mm — минуты, CCYY — 4 цифры года, ss — секунды. При этом, значения CCYY.ss указывать не обязательно.
ntp-server:~# date 121720062010.30 Птн Дек 17 20:06:30 MSK 2010
Как видно, указанная команда установит текущие дату и время на 27 декабря 2010года, 20:06:30. Команда date без параметров, выводить текущее системное время. У данной команды есть куча параметров, с которыми можно ознакомиться в man date.
Так же, необходимо правильно настроить аппаратные часы и часовой пояс. Как говорилось выше, часовой пояс настраивается копированием необходимого файла зоны из каталога /usr/share/zoneinfo/ в файл/etc/localtime:
ntp-server:~# cp /usr/share/zoneinfo/Europe/Moscow /etc/localtime
Аппаратные часы я настроил на UTC:
[ntp1@proxy ~]# cat /etc/sysconfig/clock | grep UTC
# UTC=true indicates that the clock is set to UTC;
UTC=true
ntp2-server:~# cat /etc/default/rcS | grep UTC
UTC=yes
В первом примере указан конфигурационный файл, определяющий использование UTC для RH, второй - для Deb-дистрибутивов.
Кроме установки настроек на использование времени в формате UTC, необходимо задать аппаратное время. (в большинстве случаев в этом нет необходимости, потому что заданное системное время неизбежно синхронизируется с аппаратным, силами ядра). Но все же, если у вас есть желание это сделать... Команда hwclock читает и устанавливает аппаратные часы на основании переданных ему параметров. Доступные параметры описаны в странице руководства команды. Вот несколько примеров использования hwclock:
ntp-server# hwclock # считывает время из аппаратных часов
ntp-server# hwclock --systohc --utc # устанавливает время аппаратных часов равным
# UTC на основании системного времени
ntp-server# hwclock --systohc # устанавливает время аппаратных часов
# равным местному на основании системного времени
ntp-server# hwclock --set --date "22 Mar 2002 13:17" # устанавливает время аппаратных часов
# равным указанной строке
Другим вариантом изменения времени в аппаратных часах - это доступ в BIOS при загрузке системы. Поскольку время ОС независимо от аппаратных часов, любые изменения в BIOS будут учтены при следующей загрузке.
Теперь, когда у нас все подготовлено и установлено, приступим к настройке.
Управление демоном ntpd
Управление демоном ntpd ничем не отличается от управления любыми другими демонами. Запуск или перезапуск службы ntpd:
#/etc/init.d/ntp start
#/etc/init.d/ntp restart
Остановка:
#/etc/init.d/ntp stop
Или:
#/bin/kill `cat /var/run/ntpd.pid`
Демон имеет следующие параметры запуска:
-p - PID-файл,
-g - разрешить переход на большой скачек времени
-c - конфиг файл
-q - принудительная ручная синхронизация
Настройка сервера ntpd
Первым делом, посоветую изменить параметры запуска демона в следующем конфигурационном файле :
Debian:
ntp-server:~# cat /etc/default/ntp
NTPD_OPTS='-g'
RedHat:
[ntp2@proxy ~]# cat /etc/sysconfig/ntpd
# Parameters for NTP daemon.
# See ntpd(8) for more details.
....
# Specifies additional parameters for ntpd.
NTPD_ARGS="-g"
Данный параметр позволит синхронизировать часы, даже если образовалась очень большая разница во времени.
Итак, как я уже говорил, информация о конфигурации демона ntpd лежит в файле /etc/ntp.conf. Синтаксис файла стандартен, как и во многих других конфигах: пустые строки и строки, начинающиеся с символа "#" игнорируются. Вот простой пример:
ntp-server:~# cat /etc/ntp.conf
server ntplocal.example.com prefer
server timeserver.example.org
server ntp2a.example.net
driftfile /var/db/ntp.drift
Параметр server задает, какие серверы будут использоваться для синхронизации, по одному в каждой строке. Если сервер задан с аргументом prefer, как ntplocal.example.com, то этому серверу отдается предпочтение перед остальными. Ответ от предпочтительного сервера будет отброшен, если он значительно отличается от ответов других серверов, в противном случае он будет использоваться безотносительно к другим ответам. Аргумент prefer обычно используется для серверов NTP, о которых известно, что они очень точны, такими, на которых используется специальное оборудование точного времени.
Параметр driftfile задает файл, который используется для хранения смещения частоты системных часов. На сколько я понял, данный файл постоянно хранит какое-то значение, которое формируется на основании анализа прошедших корректировок времени и если внешние источники времени становятся недоступны, то корректировка времени происходит по значению из файла drift. Он не должен изменяться никакими другими процессами. И перед указанием данного файла в конфигурации - файл должен быть создан.
По умолчанию сервер NTP будет доступен всем хостам в Интернет. Параметр restrict в файле /etc/ntp.conf позволяет вам контролировать, какие машины могут обращаться к вашему серверу. Если вы хотите запретить всем машинам обращаться к вашему серверу NTP, добавьте следующую строку в файл /etc/ntp.conf:
restrict default ignore
Если вы хотите разрешить синхронизировать свои часы с вашим сервером только машинам в вашей сети, но запретить им настраивать сервер или быть равноправными участниками синхронизации времени, то вместо указанной добавьте строчку:
restrict 192.168.1.0 mask 255.255.255.0 nomodify notrap
где 192.168.1.0 является IP адресом вашей сети, а 255.255.255.0 её сетевой маской. /etc/ntp.conf может содержать несколько директив restrict.
Для корректной и более точной работы демона, желательно выбрать сервера уровня - от stratum 2 (можно конечно stratum1, но придется убить время на поиски такого сервера) и из выбранных stratum 2 те, до которых минимальное "расстояние". Обычно такие сервера могут предоставляться вашим провайдером. Количество выбираемых серверов желательно - более 2-х 3-х, чем больше тем лучше, но в разумных пределах. Если Вам лень выбирать лучшие сервера, то можно взять список открытых серверов второго уровня отсюда: http://support.ntp.org/bin/view/Servers/StratumTwoTimeServers.
Выбираем список эталонных NTP серверов
Идем по указанному адресу (http://support.ntp.org/bin/view/Servers/StratumTwoTimeServers) и подбираем список начальных серверов. Из данного списка выбираем удовлетворяющий нашим требованиям серверы, с помощью анализа вывода команды ntpdate. При выполнении команды, применяется следующий синтаксис:
ntpdate параметры серверы_через_пробел
Для того чтобы наш запрос не вносил изменения в систему, необходимо использовать параметр -q, который указывает на использование запроса без внесения изменений. Так же, возможно использовать ключ -d, указывающий, что команда будет выполняться в отладочном режиме, с выводом дополнительных сведений, без внесения реальных изменений (при данном ключе выводится куча другого мусора :), который нам в данный момент не нужен ). Остальные параметры можно посмотреть в man 8 ntpdate. Из указанной ссылки я выбрал все сервера Open Access, расположенные в России (RU) + тот, который предоставил провайдер и запустил команду, получилось примерно следующее:
ntp-server:~# ntpdate -q ntp2.ntp-servers.net ntp1.vniiftri.ru ntp2.vniiftri.ru ntp4.vniiftri.ru ntp0.ntp-servers.net ntp1.ntp-servers.net ntp3.vniiftri.ru ntp.corbina.net
server 88.147.255.85, stratum 1, offset 0.006494, delay 0.09918
server 62.117.76.142, stratum 1, offset 0.002552, delay 0.06920
server 62.117.76.141, stratum 1, offset 0.003147, delay 0.06918
server 62.117.76.140, stratum 1, offset 0.004823, delay 0.07350
server 88.147.254.228, stratum 1, offset -0.002355, delay 0.12030
server 88.147.254.229, stratum 1, offset -0.000922, delay 0.10577
server 62.117.76.138, stratum 1, offset 0.005331, delay 0.07401
server 195.14.40.141, stratum 2, offset 0.002846, delay 0.07188
13 Jan 19:14:09 ntpdate[1946]: adjust time server 62.117.76.141 offset 0.003147 sec
В примере наши сервера удачно выдали уровень stratum1, что не может не радовать (кроме сервера провайдера ), offset - это расхождение во времени с этим сервером в секундах, delay - задержка синхронизации в секундах. Обычно, бОльшая точность получается при использовании серверов, которые имеют низкую задержку передачи пакетов по сети. Для выявления этого, возможно воспользоваться утилитами ping и traceroute. Соответственно, выбрав сначала те, у которых время ответа меньше, а из них - те, до которых меньше хопов. Я же, чтобы не терять время, воспользуюсь всем указанными серверами и впишу их в конфигурационный файл. Итого, зная все вышеперечисленное, опишу свой получившийся файл /etc/ntp.conf:
ntp-server:~# cat /etc/ntp.conf
# Сервера локальной сети (закомментированы, не используются - в сети один сервер)
#server 192.168.0.2
#server 192.168.0.5
# интернет-сервера
server ntp2.ntp-servers.net
server ntp1.vniiftri.ru
server ntp2.vniiftri.ru
server ntp4.vniiftri.ru
server ntp0.ntp-servers.net
server ntp1.ntp-servers.net
server ntp3.vniiftri.ru
server ntp.corbina.net
# Файлы сервера
driftfile /var/lib/ntp/ntp.drift
logfile /var/log/ntpstats
# ограничение доступа к серверу:
# по умолчанию игнорируем все
restrict default ignore
# локалхост без параметров - значит разрешено все. Параметры идут только на запреты.
restrict 127.0.0.1
# далее описываются сервера с которыми мы синхронизируемся в локальной сети.
# Разрешаем им все кроме трапов и запросов к нам
restrict 192.168.0.2 noquery notrap
restrict 192.168.0.5 noquery notrap
# для локалки так же разрешаем все, кроме трапов и модификаций
restrict 192.168.0.1 mask 255.255.255.0 nomodify notrap nopeer
# разрешаем внешним источникам времени доступ:
restrict ntp2.ntp-servers.net
restrict ntp1.vniiftri.ru
restrict ntp2.vniiftri.ru
restrict ntp4.vniiftri.ru
restrict ntp0.ntp-servers.net
restrict ntp1.ntp-servers.net
restrict ntp3.vniiftri.ru
restrict ntp.corbina.net
# а этот хак, который выставляет уровень доверия серверу (strata) самому себе равный 3
# в двух словах чем выше уровень-тем меньше число. 0 - это атомные часы,
# 1 - это синхронизированные с ними, 2 - с первым, и так далее.
server 127.127.1.1
fudge 127.127.1.1 stratum 3
Для более углубленного понимания и настройки сервера, опишу некоторые параметры конфигурации ntpd, о которых не упоминал::
- enable/disable auth/monitor/pll/pps/stats - включить/выключить режим работы:
- auth - с неупомянутыми соседями общаться только в режиме аутентификации;
- monitor - разрешить мониторинг запросов;
- pll - разрешить настраивать частоту местных часов по NTP;
- stats - разрешить сбор статистики;
- statistics loopstats - при каждой модификации локальных часов записывает строчку в файл loopstats;
- statistics peerstats - каждое общение с соседом записывается в журнал, хранящийся в файле peerstats;
- statistics clockstats - каждое сообщение от драйвера локальных часов записывается в журнал, хранящийся в файле clockstats;
- statsdir {имя_каталого_со_статистикой} - задает имя каталога, в котором будут находится файлы со статистикой сервера;
- filegen [file {filename}] [type {typename}] [flag {flagval}] [link|nolink] [enable|disable]- определяет алгоритм генерации имен файлов, которые состоят из:
- префикс - постоянная часть имени файла, задается либо при компиляции, либо специальными командами конфигурации;
- имя файла - добавляется к префиксу без косой черты, две точки запрещены, может быть изменена ключем file;
- суффикс - генерируется в зависимости от typename;
- restrict numeric-address [mask {numericc-mask}] [flag] - задает ограничение доступа: пакеты сортируются и маскам, берется исходный адрес и последовательно сравнивается, от последнего удачного сравнения берется флаг [flag]доступа:
- нет флагов - дать доступ;
- ignore - игнорировать все пакеты;
- noquery - игнорировать пакеты NTP 6 и 7 (запрос и модификация состояния);
- nomodify - игнорировать пакеты NTP 6 и 7 (модификация состояния);
- limited - обслуживать только ограниченное количество клиентов из данной сети;
- nopeer - обслуживать хост, но не синхронизироваться с ним;
- clientlimit limit - для флага limited определяет максимальное количество обслуживаемых клиентов (по дефолту 3);
Итого, мы получили ntpd-server, который синхронизируется с внешним миром, позволяет получать время для клиентов из локальной сети 192.168.0.1 с маской 255.255.255.0, а так же может синхронизироваться с локальным сервером (если раскомментировать несколько строк). Нам осталось настроить клиентов и узнать, как наблюдать за нашим сервером.
Наблюдение за сервером ntpd и за синхронизацией
Когда у вас все настроено. NTP будет держать время в синхронизированном состоянии. Этот процесс можно наблюдать при помощи команды NTP Query (ntpq):
ntp-server:~# ntpq -p
remote refid st t when poll reach delay offset jitter
==============================================================================
-n3.time1.d6.hsd .PPS. 1 u 34 64 177 70.162 2.375 8.618
+ntp1.vniiftri.r .PPS. 1 u 33 64 177 43.479 -0.020 10.198
*ntp2.vniiftri.r .PPS. 1 u 6 64 177 43.616 -0.192 0.688
+ntp4.vniiftri.r .PPS. 1 u 4 64 177 43.623 0.440 0.546
-n1.time1.d6.hsd .PPS. 1 u 53 64 77 92.865 -11.358 38.346
-ns1.hsdn.org .GPS. 1 u 40 64 177 78.057 -3.292 35.083
-ntp3.vniiftri.r .PPS. 1 u 44 64 77 47.667 2.292 2.611
-scylla-l0.msk.c 192.43.244.18 2 u 62 64 77 41.565 -1.564 28.914
Данная команда с ключом -p выводит на стандартный вывод список источников времени с их характеристиками (остальные параметры команды в man ntpq). Значение каждой колонки следующее:
remote
Имя удаленного NTP-сервера. Если указать ключ -n, вы получите IP-адреса серверов вместо имён.
refid
Указывает, откуда каждый сервер получает время в данный момент. Это может быть имя хоста или что-то вроде .GPS., указывающее на источник глобальной системы позиционирования (Global Positioning System).
st
Stratum (уровень) это число от 1 до 16, указывающее на точность сервера. Единица означает максимальную точность, 16 -- сервер недоступен. Ваш уровень будет равен уровню наименее точного удаленного сервера плюс 1.
poll
Интервал между опросами (в секундах). Значение будет изменяться между минимальной и максимальной частотой опросов. В начале интервал будет маленьким, чтобы синхронизация происходила быстро. После того как часы синхронизируются, интервал начинает увеличиваться, чтобы уменьшить трафик и нагрузку на популярные сервера времени.
reach
Восьмеричное представление массива из 8 бит, отражающего результаты последних восьми попыток соединения с сервером. Бит выставлен, если удаленный сервер ответил.
delay
Количество времени (в секундах) необходимого для получения ответа на запрос "который час? ".
offset
Наиболее важное поле. Разница между временем локального и удаленного серверов. В ходе синхронизации это значение должно понижаться (приближаться к нулю), указывая на то, что часы локальной машины идут все точнее.
jitter
Дисперсия (Jitter) -- это мера статистических отклонений от значения смещения (поле offset) по нескольким успешным парам запрос-ответ. Меньшее значение дисперсии предпочтительнее, поскольку позволяет точнее синхронизировать время.
Значение знаков перед именами серверов
x - фальшивый источник по алгоритму пересечения;
. - исключён из списка кандидатов из-за большого расстояния;
- - удалено из списка кандидатов алгоритмом кластеризации;
+ - входит в конечный список кандидатов;
# - выбран для синхронизации, но есть 6 лучших кандидатов;
* - выбран для синхронизации;
o - выбран для синхронизации, но используется PPS;
пробел - слишком большой уровень, цикл или явная ошибка;
Служба ntpd "умная" и сама отсеивает источники времени слишком выбивающиеся за рамки разумного. Через некоторое время после запуска ntpd выберет наиболее достоверные источники данных и будет синхронизироваться с ними. Представленный нами список эталонных NTP серверов регулярно пересматривается службой.
Проверить возможность синхронизации локально на сервере возможно командой:
ntp-server:~# ntpdate -q localhost
server 127.0.0.1, stratum 2, offset -0.000053, delay 0.02573
server ::1, stratum 2, offset -0.000048, delay 0.02571
14 Jan 14:49:57 ntpdate[2231]: adjust time server ::1 offset -0.000048 sec
Из вывода команды видно, что наш сервер уже стал уровня stratum 2. Для достижения данного уровня, необходимо некоторое время. Возможно, в первые 10-15 минут уровень сервера будет выше.
О корректной работе сервера ntp можно так же судить по логам демона ntpd:
ntp-server:~# cat /var/log/ntpstats/ntp
13 Jan 20:13:16 ntpd[1764]: Listening on interface #5 eth0, fe80::a00:27ff:fec1:8059#123 Enabled
13 Jan 20:13:16 ntpd[1764]: Listening on interface #6 eth0, 192.168.0.8#123 Enabled
14 Jan 14:31:00 ntpd[2217]: synchronized to 62.117.76.142, stratum 1
14 Jan 14:31:10 ntpd[2217]: time reset +10.291312 s
14 Jan 14:31:10 ntpd[2217]: kernel time sync status change 0001
14 Jan 14:34:31 ntpd[2217]: synchronized to 88.147.255.85, stratum 1
14 Jan 14:36:04 ntpd[2217]: synchronized to 62.117.76.141, stratum 1
14 Jan 15:04:36 ntpd[2217]: synchronized to 62.117.76.142, stratum 1
14 Jan 15:10:58 ntpd[2217]: synchronized to 62.117.76.140, stratum 1
14 Jan 15:17:54 ntpd[2217]: no servers reachable
14 Jan 15:31:49 ntpd[2217]: synchronized to 62.117.76.140, stratum 1
14 Jan 15:32:14 ntpd[2217]: time reset +13.139105 s
Настройка netfilter (iptables) для NTP сервера
Настроив работу сервера, неплохо было бы его защитить. Мы знаем, что сервер работает на 123/udp порту, при этом запросы так же отправляются с порта 123/udp. Ознакомившись со статьей, что такое netfilter и правила iptables и ознакомившись с практическими примерами iptables, можно создать правила фильтрации сетевого трафика:
ntp ~ # iptables-save
# типовые правила iptables для DNS
*filter
:INPUT DROP [7511:662704]
:FORWARD DROP [0:0]
:OUTPUT DROP [0:0]
-A INPUT -i lo -j ACCEPT
-A INPUT -m conntrack --ctstate RELATED,ESTABLISHED -j ACCEPT
-A INPUT -m conntrack --ctstate INVALID -j DROP
# разрешить доступ локальной сети к NTP серверу:
-A INPUT -s 192.168.1.1/24 -d 192.168.1.1/32 -p udp -m udp --dport 123 -m conntrack --ctstate NEW -j ACCEPT
-A OUTPUT -o lo -j ACCEPT
-A OUTPUT -p icmp -j ACCEPT
-A OUTPUT -p udp -m udp --sport 32768:61000 -j ACCEPT
-A OUTPUT -p tcp -m tcp --sport 32768:61000 -j ACCEPT
-A OUTPUT -m conntrack --ctstate RELATED,ESTABLISHED -j ACCEPT
# разрешить доступ NTP серверу совершать исходящие запросы
-A OUTPUT -p udp -m udp --sport 123 --dport 123 -m conntrack --ctstate NEW -j ACCEPT
COMMIT
Это типовой пример! Для задания правил iptables под Ваши задачи и конфигурацию сети, необходимо понимать принцип работы netfilter в Linux, почитав вышеуказанные статьи.
Настройка клиентских машин
Для синхронизации времени на UNIX-машинах локальной сети целесообразно использовать утилиту ntpdate, запуская ее при помощи демона cron несколько раз в сутки, например каждый час. Для этого, в кронтаб пользователя root необходимо добавить следующую строку:
0 * * * * /usr/sbin/ntpdate -s <IP-адрес или FQDN-имя NTP-сервера локальной сети>
Ключ -s направляет вывод команды демону syslog. Если на клиентских машинах есть пару лишних мегабайт оперативки, то можно запустить демон ntpd, как и на сервере со следующим конфигом:
server <IP-адрес или FQDN-имя NTP-сервера локальной сети>
restrict default ignore
restrict <IP-адрес или FQDN-имя NTP-сервера локальной сети> noquery notrap
restrict 127.0.0.1 nomodify notrap
Думаю, в данном конфиге все понятно: источник времени (server) - локальный ntpd-сервер, доступ всем запретить, разрешить только локальному ntpd-серверу.
Так же, на клиентах необходимо правильно указать в каком формате хранить время и выбрать правильный часовой пояс, в соответствии с теорией выше.
Для настройки NTP клиента Windows, необходимо выполнить в консоли следующие команды:
C:\>net time /setsntp:<IP-адрес или FQDN-имя NTP-сервера локальной сети>
The command completed successfully.
C:\>net stop w32time
The Windows Time service is stopping.
The Windows Time service was stopped successfully.
C:\>net start w32time
The Windows Time service is starting.
The Windows Time service was started successfully.
C:\>net time /querysntp
The current SNTP value is: <IP-адрес или FQDN-имя NTP-сервера локальной сети>
The command completed successfully